
You've likely heard the term "artificial intelligence" or "AI" used a lot in recent years. It seems like there's a new AI-powered product or service being announced every day. But what does AI actually mean? In this blog post, we'll take a deep dive into one specific aspect of AI—model inference—to help you understand what it is and how it works.
What is Model Inference?
In machine learning, model inference is the process of using a trained model to make predictions on new data. In other words, after you've taught a machine learning model to recognize certain patterns, model inference allows the model to automatically apply that knowledge to new data points and make predictions about them. For example, if you've trained a machine learning model to identify animals in pictures, model inference would allow the model to automatically identify animals in new pictures that it has never seen before.
How AI Inference Works
Model inference is performed by first preprocessing the data (if necessary) and then feeding it into the trained machine-learning model. The model will then generate predictions based on the data that was fed into it. These predictions can be used to make decisions or take actions in the real world.
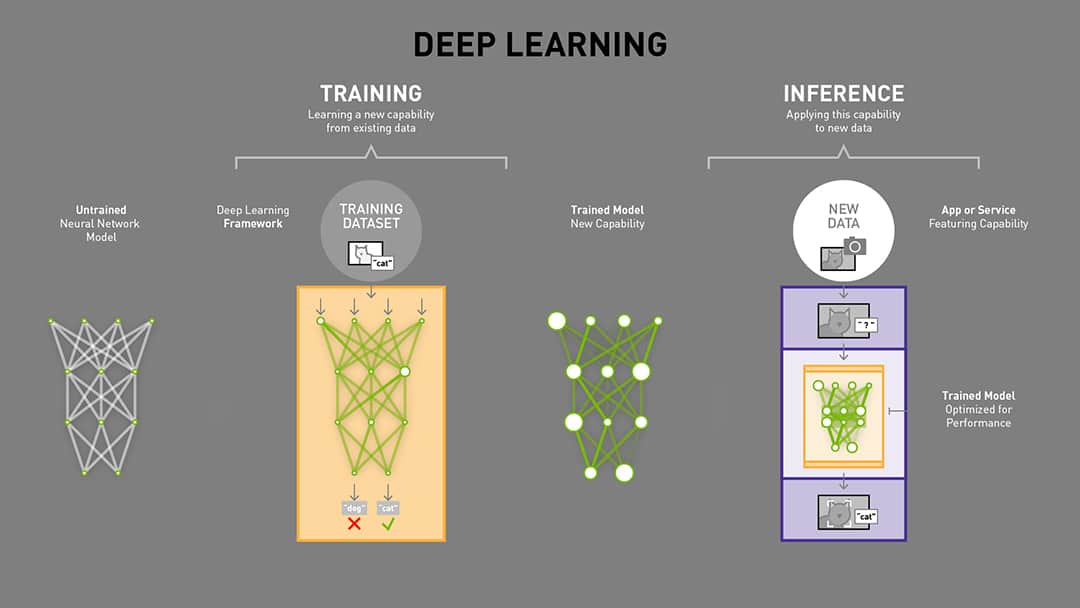
The ML model is hosted in an infrastructure where the model can run. It will expect input data in a specific format and will produce certain outputs, usually predictions with a confidence score.
For example, let's say you're running a website and you want to show different ads to different users based on their interests. You could use a machine learning model to predict each user's interests based on their browsing behavior on your website (data that you collect about their clicks, pages visited, etc.). You could then use these predictions to show each user ads that are relevant to their interests. This process—collecting data, making predictions, and taking action based on those predictions—is known as "inference."
Challenges of Model Inference
The demand for sophisticated AI-enabled services like image and speech recognition, and natural language processing has increased significantly in recent years. At the same time datasets are growing which makes models more complex to process data with latency requirements tightening due to user expectations.
While model inference might seem like a simple concept, there are actually a lot of challenges that can arise during the process. One of those challenges is latency. So, what exactly is latency? And how can data scientists overcome it? Let's take a closer look.
Latency refers to the amount of time that elapses between when an ML model is deployed and when it's able to start making predictions. For example, if you have an e-commerce website and you deploy a model that predicts whether or not a customer will add an item to their cart, there will be some latency between when the customer arrives on your website and when the model makes its prediction. During that time, your customer might get impatient and leave without making a purchase.
There are a few different ways that data scientists can reduce latency and make sure their models are able to make predictions in real-time. One way is to use serverless computing, which allows models to be deployed without the need for infrastructure management. Another way is to use edge devices, which bring computation closer to the data sources (i.e., customers in our e-commerce example). By using edge devices, data doesn't have to travel as far to reach the model, which cuts down on processing time and increases prediction speed.
GPU computing has been an integral part of the AI landscape since its inception. GPUs provide the power needed to train and execute large-scale neural networks. AI practitioners have a limited choice in selecting high-performance hardware inference solutions. Due to the dependencies in complex runtime environments, maintaining the code that makes up these solutions becomes challenging. Meta recently Open Sourced AITemplate (AIT), a unified open-source system with separate acceleration back ends for both AMD and NVIDIA GPU hardware technology. Researchers at Meta AI used AITemplate to improve performance up to 12x on NVIDIA GPUs and 4x on AMD GPUs.
AI at the edge
Traditionally, the inference is done on central servers in the cloud. However, recent advancements in edge computing are making it possible to do model inference on devices at the edge of the network. For some use cases, that is very critical, like in self-driving cars.
There are several advantages to deploying models on devices at the edge. First, it reduces latency because data does not have to be sent to the cloud for processing. Second, it conserves bandwidth because only the results of the inference need to be transmitted, rather than the entire dataset. And third, it can provide better privacy protection since sensitive data never leaves the device.
Think about Inference in your next AI Project!
AI inference is a vital part of artificial intelligence—it's what allows machines to make predictions about new data points. If you're running a business, understanding how inference works can help you make better decisions about how to use AI to improve your products and services. And if you're interested in pursuing a career in AI, developing strong inference skills will be critical.
The deep learning industry has been growing at a rapid pace, and as such there are now more models available to train on than ever before. This creates an issue when you need access to your trained model in order for it to do its job - namely predictions!