
As a business owner, you are always looking for ways to improve your bottom line. One way that has been suggested is to deploy AI models to help with decision-making. However, deploying AI models is known to be difficult for a few reasons.
First, usually, AI models often require large amounts of data in order to be trained. This data may not be readily available or it may be prohibitively expensive to obtain. Second, AI models can be difficult to configure and tune correctly. Often times they need to be fine-tuned over time in order to produce the best results. Finally, AI models can be unpredictable and their results can vary from one situation to the next. This makes it difficult to rely on them for critical business decisions.
Despite these challenges, there are many businesses that have been successful in deploying ai models. However, it takes careful planning and execution in order to make it work.
What is Operationalizing ML?
Per Wikipedia, MLOps is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
Operationalizing machine learning (ML) involves using engineers to continuously collect data, experiment with improving performance, and monitor the results in production. MLOps is the process of deploying and maintaining a machine learning pipeline in production. The 4 tasks that ML engineers use are Data Collection, Experimentation, Evaluation & Deployment, and Monitoring & Response.

Biggest challenges of MLOps
The five biggest challenges facing businesses that are hoping to use machine learning or AI in their operations are data availability, lack of transparency into how algorithms make decisions about what content goes online and why they decided upon certain results rather than others, maintaining consistent quality control when scaling up production runs due both increasing volume and diversity across different sources of input – something which becomes increasingly challenging as you grow larger. Another big challenge is the potential for bias in data sets which can lead to inaccurate decision-making. Finally, there is the question of who actually “owns” these new technologies and the massive amounts of data being generated by them – a thorny issue with significant legal implications.
There are three main aspects to consider when implementing MLOPs:
- Deployment: How will the model be deployed? There are a few options here, such as containerization (e.g. Docker, Kubernetes), serverless (e.g. AWS Lambda), or on-premises (e.g. physical hardware).
- Monitoring: How will you monitor the performance of the deployed model? This includes things like logging, metric collection, and handling alerts
- Lifecycle management: What processes will be put in place to manage the lifecycle of the machine learning model? This includes things like versioning (e.g. using a tool like Git), drift detection (e.g. using a tool like Jenkins), bias mitigation or re-training.
Depending on the size and complexity of your organization, you may need to consider additional factors when implementing MLOps. But these are the three main considerations that should be taken into account regardless of organizational size or complexity.
Implementing MLOps
Now that we've gone over what MLOps are and what factors need to be considered when implementing them, let's take a look at how to actually go about doing it.
- Define Your Use Case: The first step is to define your use case—that is, what problem are you trying to solve with machine learning? Once you've identified your use case, you can move on to…
- Selecting Your Tools: There are many different tools available for each step of the MLOps process, so it's important to select the right ones for your use case and organizational needs. You'll also want to consider things like ease of use, cost, and support when making your selections.
- Set Up Your Infrastructure: Now it's time to set up your infrastructure—that is, deploy your selected tools and put your monitoring and lifecycle management processes in place. This will likely require some IT involvement, so make sure to involve them early on in the process.
- Train Your Model: Now it's time to train your machine learning model! Depending on the size and complexity of your data set, this could take some time—so be patient and don't expect perfect results right away.
- Evaluate Your Results & Repeat as Necessary: After your model has been trained and deployed, it's important to monitor its performance over time and make adjustments as necessary. The process never ends.
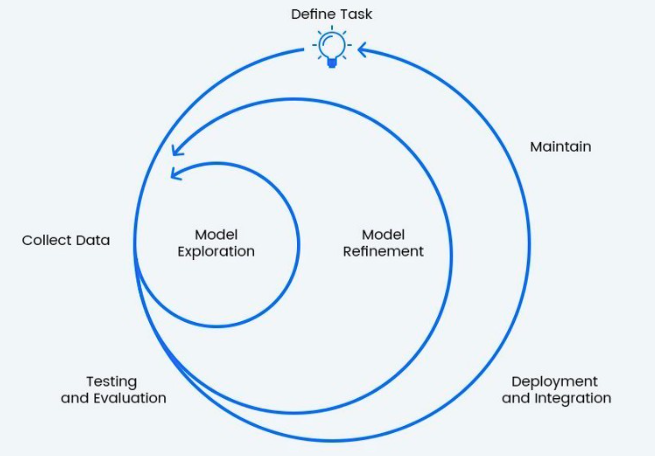
Machine learning operations is a hot topic in the business world—and for good reason! Implementing MLOps can help organizations reap the benefits of machine learning by operationalizing their models and putting them into production.
An Interview Study from Berkeley
I recently came across a very good study from Berkeley researchers Shreya Shankar, Rolando Garcia, Joseph M. Hellerstein, Aditya G. Parameswaran about Machine Learning Operationalization.
They interviewed 18 people who work with machine learning in various fields to learn about their pain points and anti-patterns to put AI into production. They recruited professionals responsible for the development, regular retraining, monitoring, and deployment of any ML models. This is a very good study that outlines the state of MLOps and some of the most common challenges that remain unaddressed in the current tools landscape. I have run into many of these issues in operationally supporting production ML models.
There is so much opportunity for MLOps Tools to mature to better support the real challenges of tracking and maintaining ML models in production. Several areas can be improved: data observability, ongoing data validation, and quality, incremental model staging controls, model performance monitoring, and business collaboration --> No-code AI will play a big role in lowering the skills required to do all that.
When conducting research on how to do MLOps, it was found that there are 3 main variables for success: Velocity, Validation, and Versioning, or what they call the three Vs. As machine learning engineering is a very experimental field, even in production there are a lot of things that can go wrong.
The full paper summarizes successful practices for ML experimentation, deployment, and sustaining production performance. I highly recommend you read it! Access the full document in the link below: