
As AI continues advancing, more companies are exploring how to leverage language models to implement multiple business use cases. One area gaining interest is small language models (SLMs). But what exactly are they and how can they benefit organizations?
Today we will cover the following:
- What are Large Language Models (LLMs)? → (a refresh)
- What are Small Language Models (SLMs)?
- Advantages of SLMs
- Benchmarks of SLMs vs LLMs
- How to tune SLMs
- Use Cases of SLMs
Let’s Dive In! 🤿
What are Large Language Models?
First, a quick reminder. A language model is a key component of natural language processing (NLP) systems, the type of AI that handles text.
These models have gained popularity for their ability to rapidly generate readable text, aiding in drafting documents, editing emails, and summarizing content. Large Language models are trained on vast amounts of text data to understand linguistic patterns and generate coherent writing and speech.
Leading LLMs have hundreds of billions to over a trillion parameters. The massive data they've trained on allows them to perform very complex language tasks, though it also increases risks of inaccuracy or unintended behavior. These are examples of LLMs and their size:
- GPT-3: 175 billion parameters
- Falcon: 180 billion parameters
- PaLM: 540 billion parameters
The size of a language model is often measured by the number of parameters. Parameters are the learned internal variables that determine the model's behavior and are updated during training.
Enterprises utilize these models for multiple use cases, but as more and more use cases are going into production we are starting to encounter limitations.
Read my Introduction to Large Language Models for more details here 👉 link
What are Small Language Models?
Enter Small Language Models or SLMs. There is no standard but I personally like to define small models containing up to 20 billion parameters. The settings the model learns from training data to carry out various text-based specific tasks. That's quite small compared to massive models like GPT-4 with 100+ billions of parameters.
Their more limited scope and data make them better suited and customizable for focused business use cases like chat, text search/analytics, and targeted content generation. They offer a sweet spot of capability versus control.
Advantages of SLMs
Does bigger always equal better when it comes to language AI? Not necessarily. Having fewer parameters gives SLMs some major advantages:
- Agile Development: Easier to build, modify, and refine quickly based on small amounts of high-quality data.
- Reduces the chances of hallucinations: Due to simpler knowledge representations and narrower training data.
- Lightweight: Enable text generation and analysis on smartphones and edge devices with lower computing requirements.
- Controllable Risks: Avoid problems like bias, toxicity, and accuracy issues more prevalent in gigantic models.
- Interpretability: The inner workings of smaller models can be understood by developers, facilitating tweaks.
- Improve Latency: Have fewer parameters, which means they can process and generate text more quickly than larger models, reducing the time it takes to generate a response or perform.
- Better sustainability: Reduced computational requirements also contribute to improved sustainability, making CO2 comparisons an important issue within the context of GreenAI.
- Reduced cost: Smaller models present notable cost savings in contrast to models like GPT-3.5 and GPT-4. The expense for generating a paragraph summary with LLaMA 2, which has three variations—7 bn, 13 bn, and 70 bn— is approximately 30 times lower than that of GPT-4, all while preserving an equivalent level of accuracy.
The speed of learning SLMs allow is huge, too. They're within the reach of so many more teams at lower cost. It just lets more innovation cycles happen faster - Brad Edwards
Benchmarks of SLMs vs LLMs
To demonstrate the power of SLMs, I will provide a few examples of task-specific benchmarks. In this section, I'll share some examples featuring popular models and use cases.
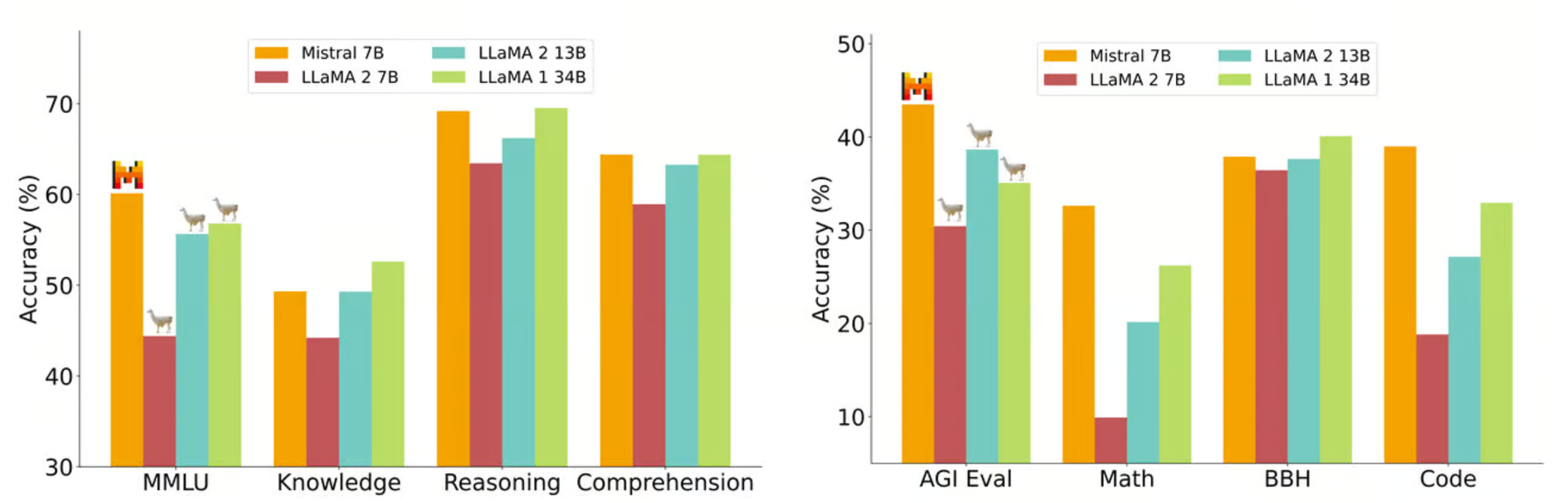
Mistral 7b
Mistral 7B is a popular Open Source model. The development team tested Mistral 7B and different Llama models on a wide range of benchmarks. Mistral 7B significantly outperforms Llama 2 13B on all metrics and is on par with Llama 34B (since Llama 2 34B was not released, we report results on Llama 34B). It is also vastly superior in code and reasoning benchmarks.
IBM Granite
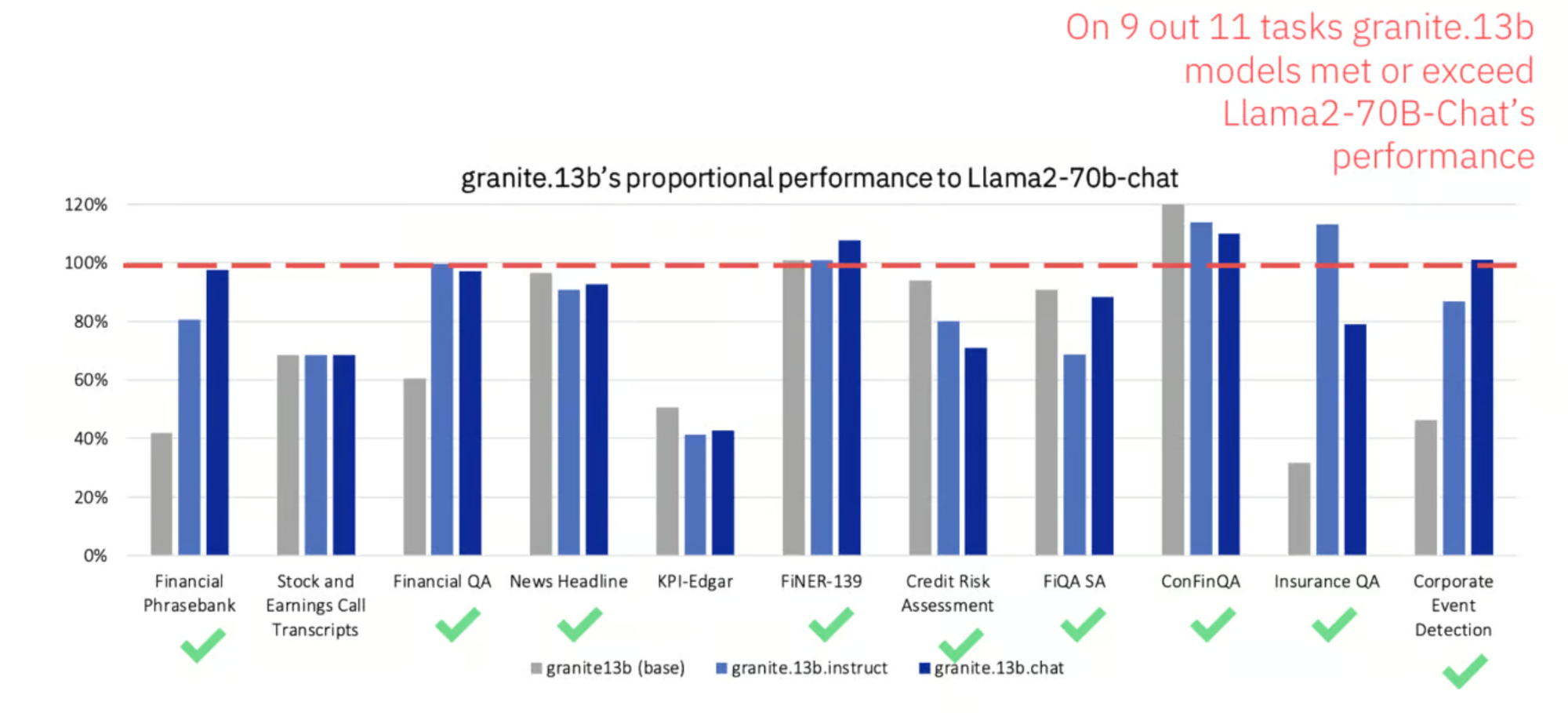
IBM released the Granite series, available on IBM watsonx. Despite having been trained on half the amount of data as the LlaMA2 models, the Granite models are competitive across each of the tasks, often meeting or outperforming LlaMA2.
In the benchmark below, Granite 13b is tested on a popular Finance Evaluation, which compares financial performance to the leading general-purpose models, in this case, Llama 2 70b. Despite being more than 5x smaller, IBM Gratine exceeded 9 out of 11 tasks. That’s because IBM Granite was trained with more and better finance industry-specific data.
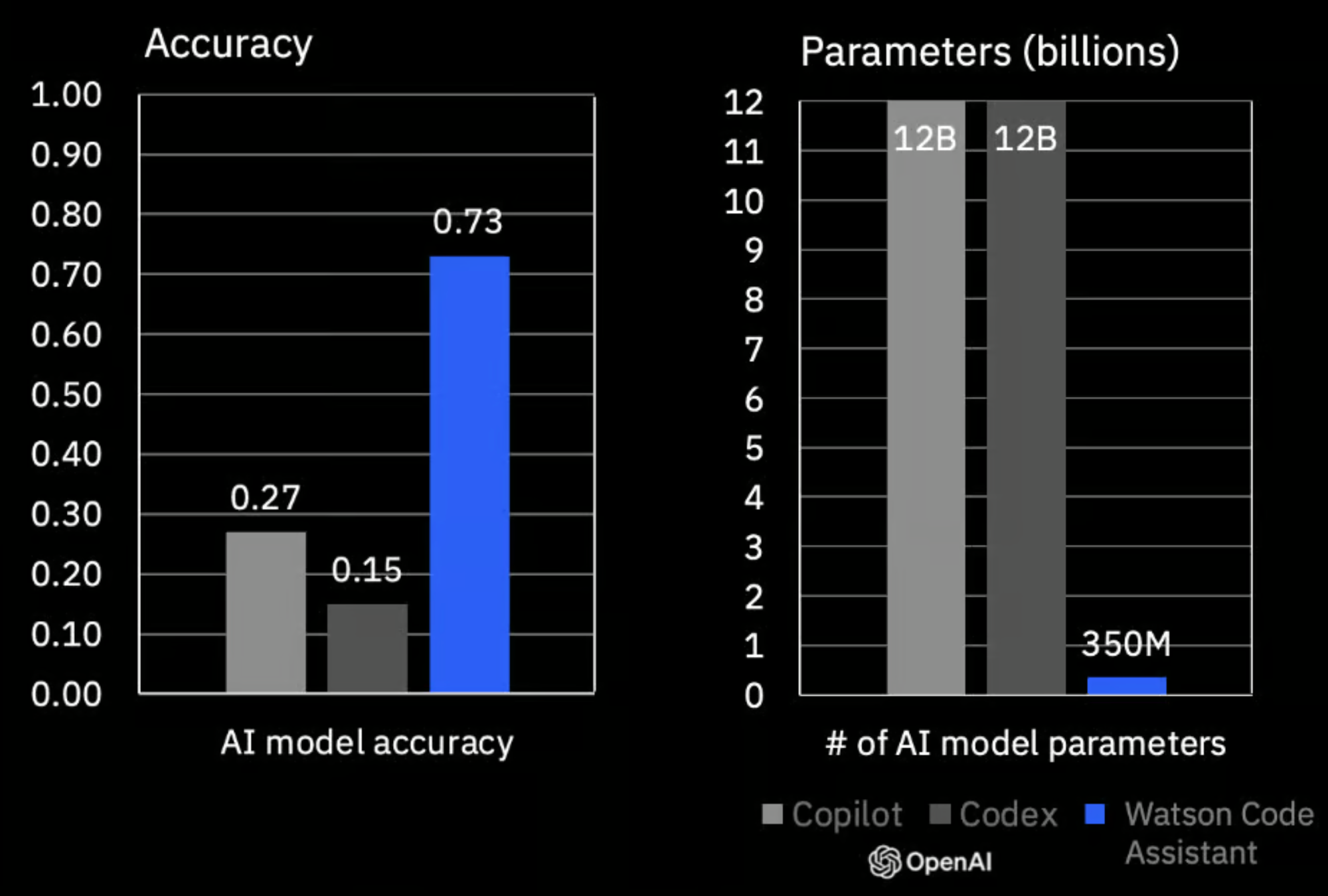
watsonx Code Assistant
watsonx Code Assistant is powered by the IBM Granite foundation models tuned with code data, geared to help IT teams create high-quality code using AI-generated recommendations based on natural language requests or existing source code. In the benchmark below, we tested how it performs generative Ansible code with a model of just 350M parameters, against Copilot with 12B or Codex with 12B. The accuracy is x6 better.
Phi-2
Microsoft recently announced Phi-2, a model with 2.7 billion parameters, showcasing state-of-the-art performance in benchmark tests, including common sense evaluations. Although complete details are pending, its predecessor, Phi-1.5, with 1.3 billion parameters, reportedly surpassed LlaMA 2's 7-billion parameter model in various benchmarks.
Microsoft loves SLMs - Satya Nadella, Chairman and CEO at Microsoft
How to tune Small Language Models
One of the primary benefits of SLMs lies in their ease of fine-tuning to attain impressive performance. Such a feature makes SLMs particularly suitable for fine-tuning, offering significant advantages to small businesses or startups eager to get into the capabilities of generative AI models.
Many use cases previously hindered from going into production due to the high cost of GPT-4 will find viability with fine-tuned versions of SLMs.
running ChatGPT costs approximately $700,000 a day
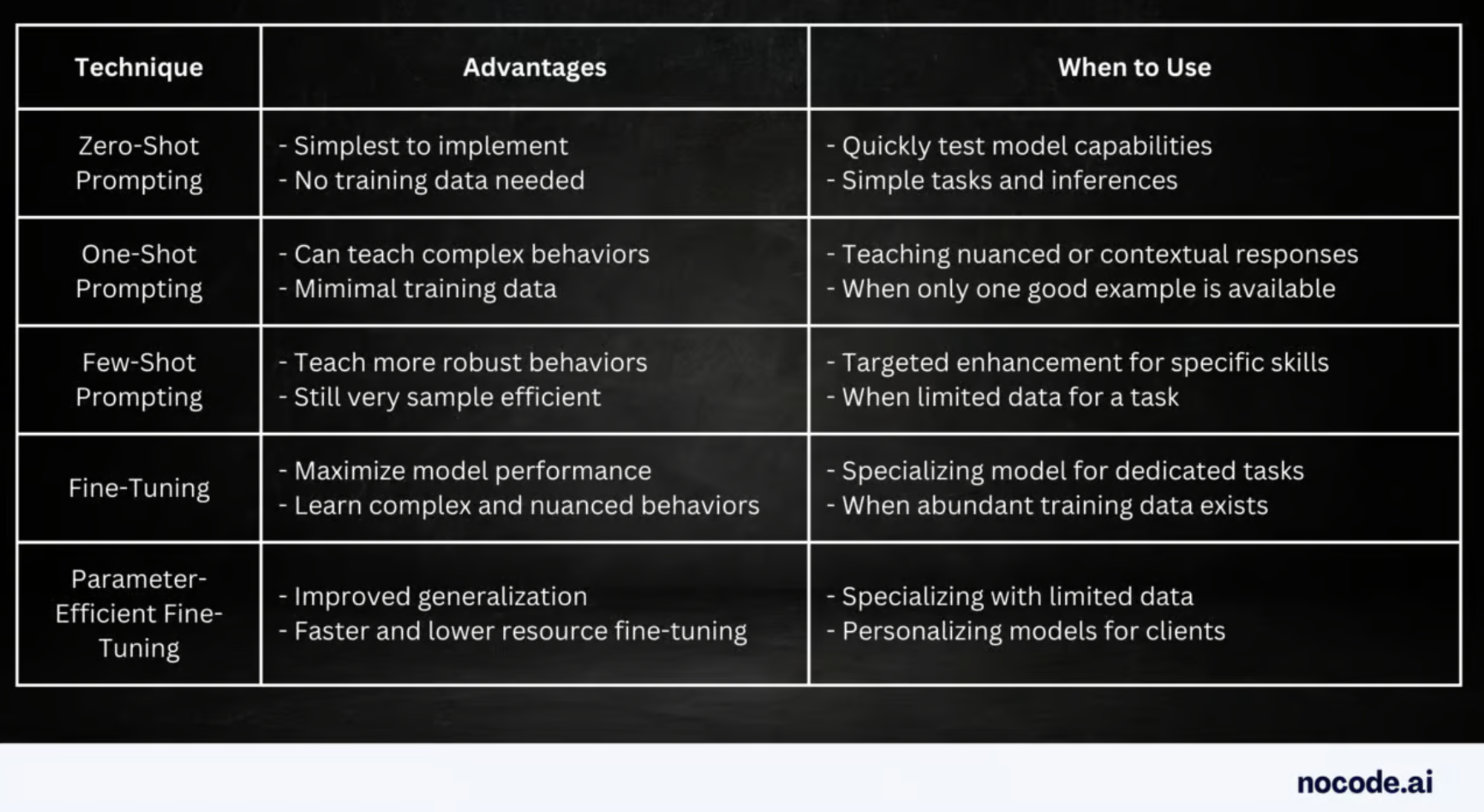
There are multiple techniques to tune SLMs, the same as LLMs. I described them in detail a few weeks back in the post How to Customize Foundation Models 👉 link
As a quick recap:
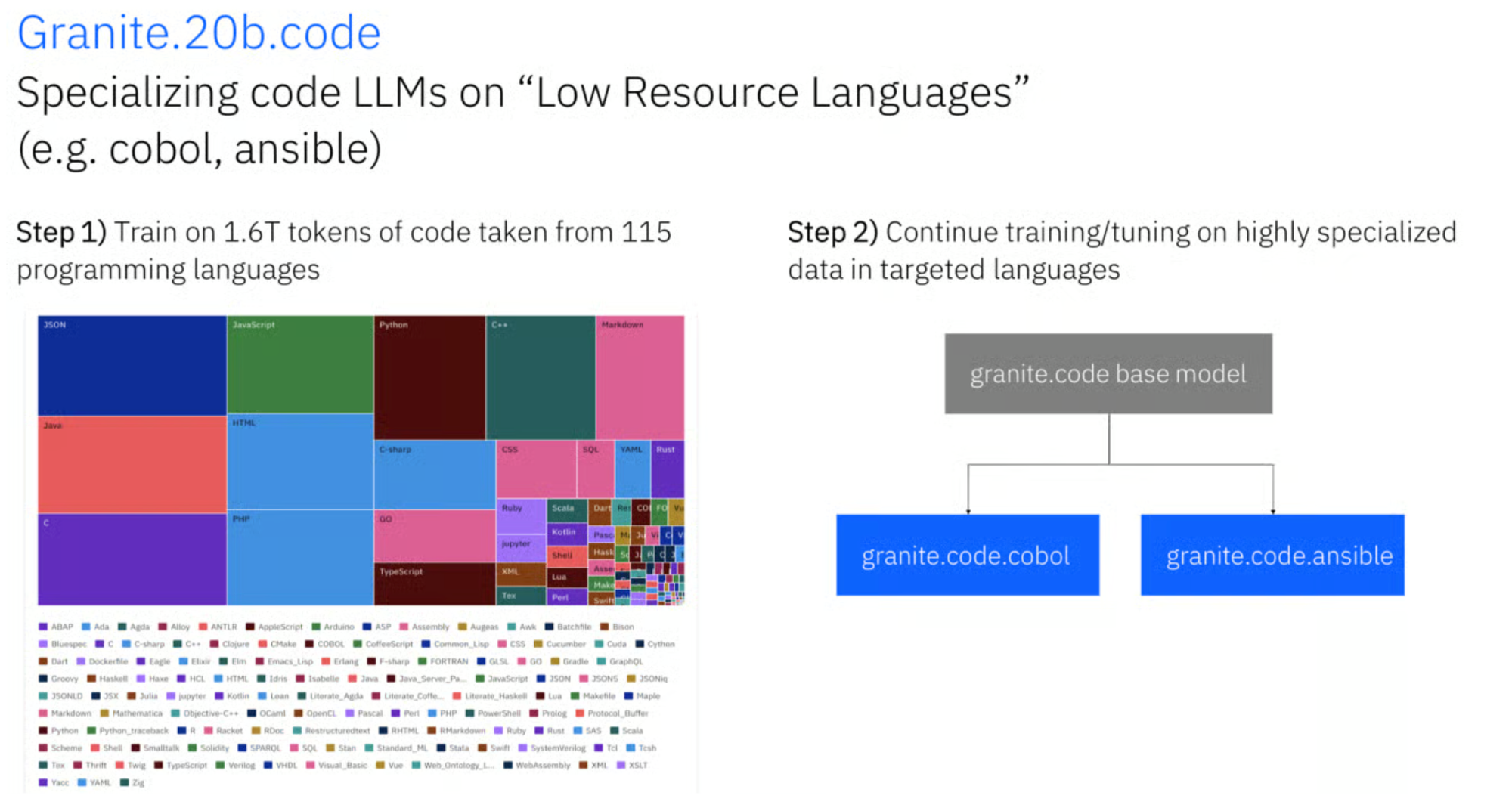
As an example, this is how IBM specialized the Granite series for code. It is a 2-step process. First, we trained the Granite model to train it with generic 1.6T tokens of code from 115 programming languages. The second step is to continue training/tuning on highly specialized data in targeted languages, in the example below Cobol and Ansible, which are “Low Resource Languages”, meaning that there isn’t a lot of data available.
A cascade of variants
The open-source aspect of LLaMA fueled considerable enthusiasm in the AI community, resulting in an array of variants that incorporated instruction tuning, human assessments, multimodality, RLHF, among other features.
I like to describe HuggingFace as the Github for AI. In the Model Hub, the Open Source community is branching out popular models and creating versions targeting different use cases and languages. For example, here’s a version of Mistral 7B specialized for Polish: https://huggingface.co/piotr-ai/polanka-7b-v0.1
The open-source community is going wild.
Use Cases for SLMs
The use cases for SLMs do not change much from LLMs, they are just more optimized implementations which makes them a good choice for applications where resources are limited or where data is scarce.
You can use them for tasks such as:
- Text Generation
- Summarization
- Chatbots
- Question-Answering
The main difference is the application. For example, you can tune these models in domains such as:
- Medical translation: SLMs can be trained on medical texts, such as research papers, clinical trials, and patient records, to accurately translate medical terms and concepts.
- Legal translation: SLMs can be trained on legal texts, such as contracts, patents, and court rulings, to accurately translate legal terms and concepts.
- Technical translation: SLMs can be trained on technical texts, such as manuals, specifications, and code, to accurately translate technical terms and concepts.
For vertical industries or specialized use, massive general-purpose LLMs such as OpenAI’s GPT 4 or Meta AI’s LLaMA can be inaccurate and non-specific, even though they contain billions or trillions of parameters.
In Summary
Wrapping up today, for many business scenarios, SLMs strike the right balance of capability versus control and practicality. As leaders look to responsibly augment operations with AI, SLMs warrant consideration as an option.
Most companies will realise that smaller, cheaper, more specialised models make more sense for 99% of AI use-cases - Clem Delangue, CEO at HuggingFace.