
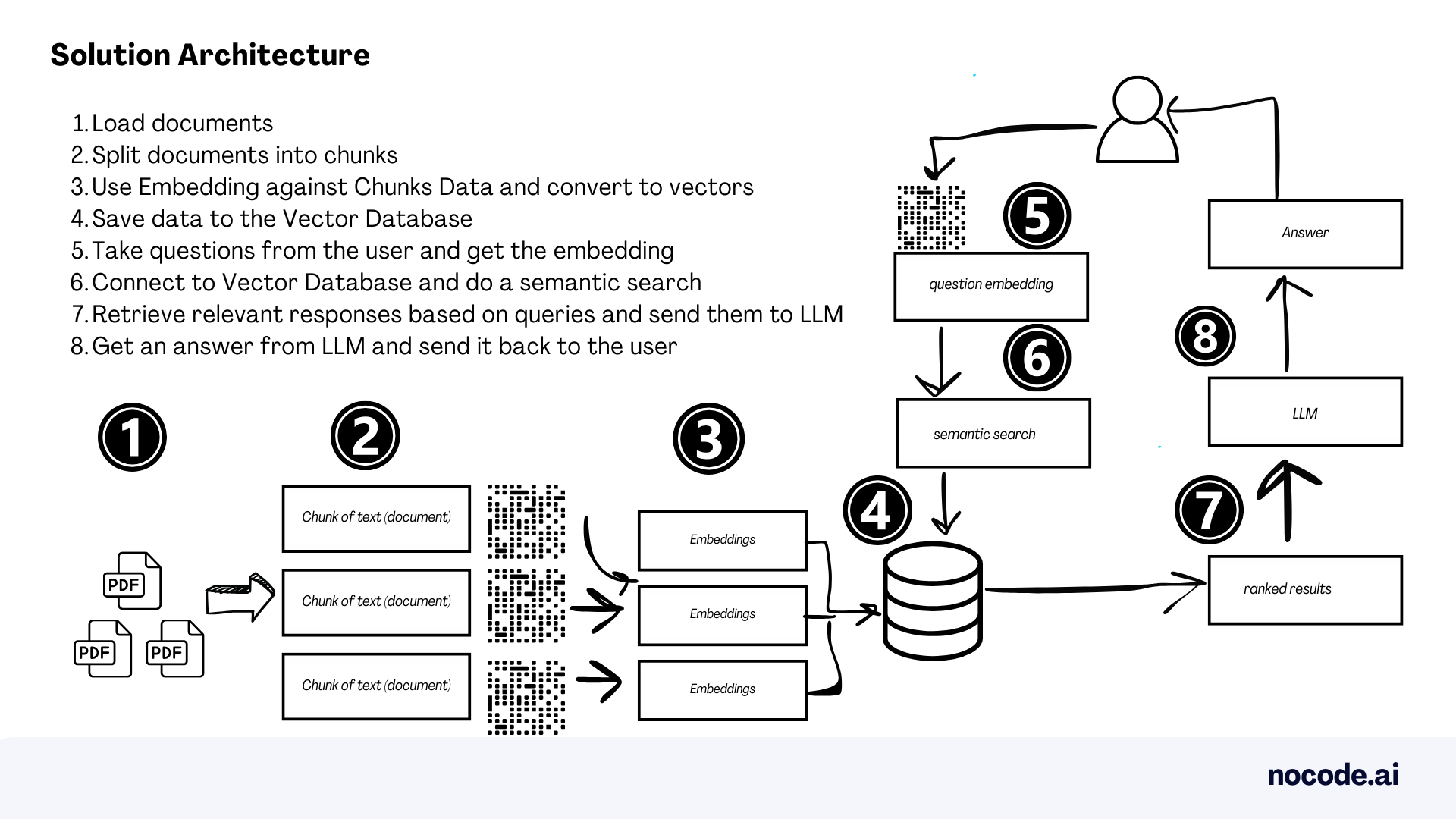
To build a chatbot to talk to your documents we will complete the following steps:
- Load documents
- Split documents into chunks
- Use Embedding against Chunks Data and convert to vectors
- Save data to the Vector Database
- Take data (question) from the user and get the embedding
- Connect to Vector Database and do a semantic search
- Retrieve relevant responses based on user queries and send them to LLM
- Get an answer from LLM and send it back to the user
😱 Seems daunting? It's not, with no-code AI tools!
Let’s dive in 🤿
The Generative AI that we will use
- LLM from OpenAI called GPT3.5, which is fast, cheap, and reliable
- Document loader to connect our PDFs
- Embeddings to convert all the text of the documents into the database. We will use the OpenAI Embeddings model called ‘text-embedding-ada-002’
- Vector Database called Weaviate, which is open source and free to use.
- Prompts to give instructions to the Chatbot
- Chains to connect all these components together.
Environment preparation
- Software that we will use: Stack-AI, a No-code AI platform to build AI solutions for multiple use cases.
- How to get access to Stack AI: go to https://www.stack-ai.com/ and hit Sign Up. There’s a Free plan that will allow us to experiment with the tool.
- Product Documentation: https://docs.stack-ai.com/stack-ai/
Demo of the tutorial
Prefer video? No problem! Here’s me showing you how to build the solution in less than 5 min
Let’s Start the tutorial! 🏁
- Once you created your account, log in to Stack AI https://www.stack-ai.com/
- Click on Dashboard
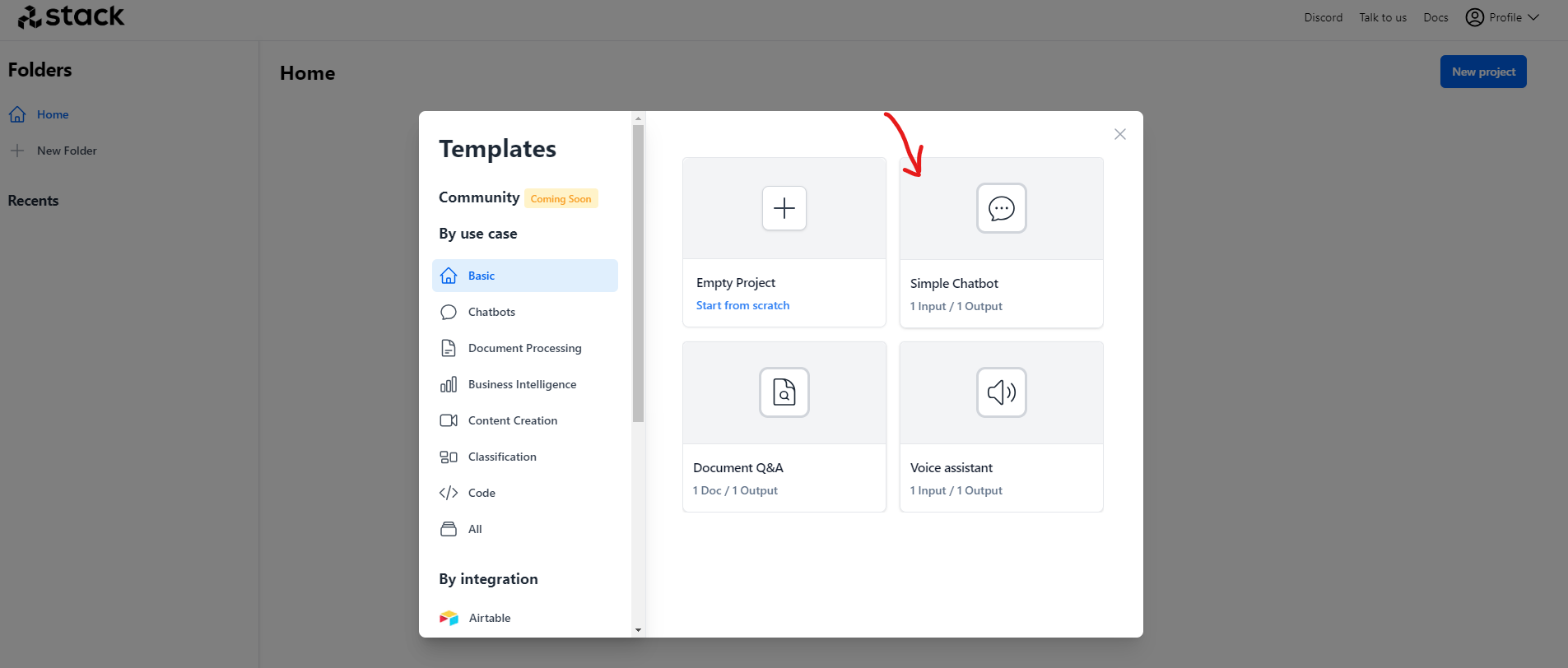
- Click on New project

4. Select Simple Chatbot
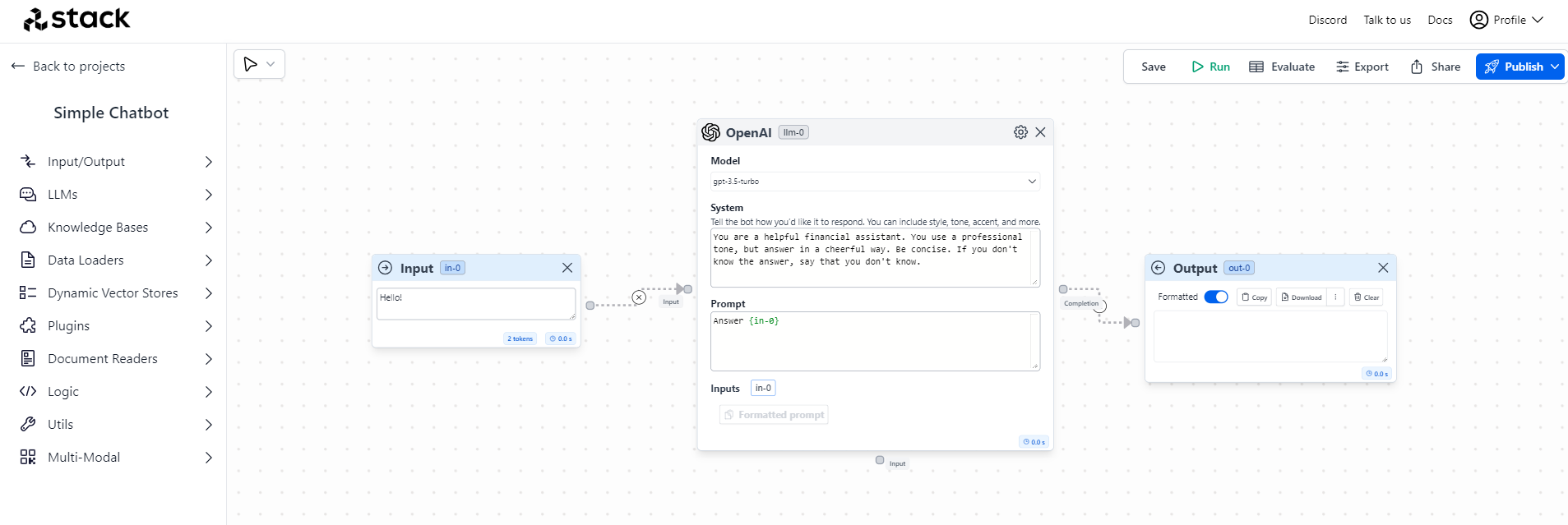
5. Welcome to the canvas to build your GenAI end-to-end solution. It already comes with three basic components:
- Input: this is where we add our questions to the Chatbot
- Model: in this case, OpenAI with GPT3.5 is already selected and we will specify the Prompt
- Output: where we will get the answer
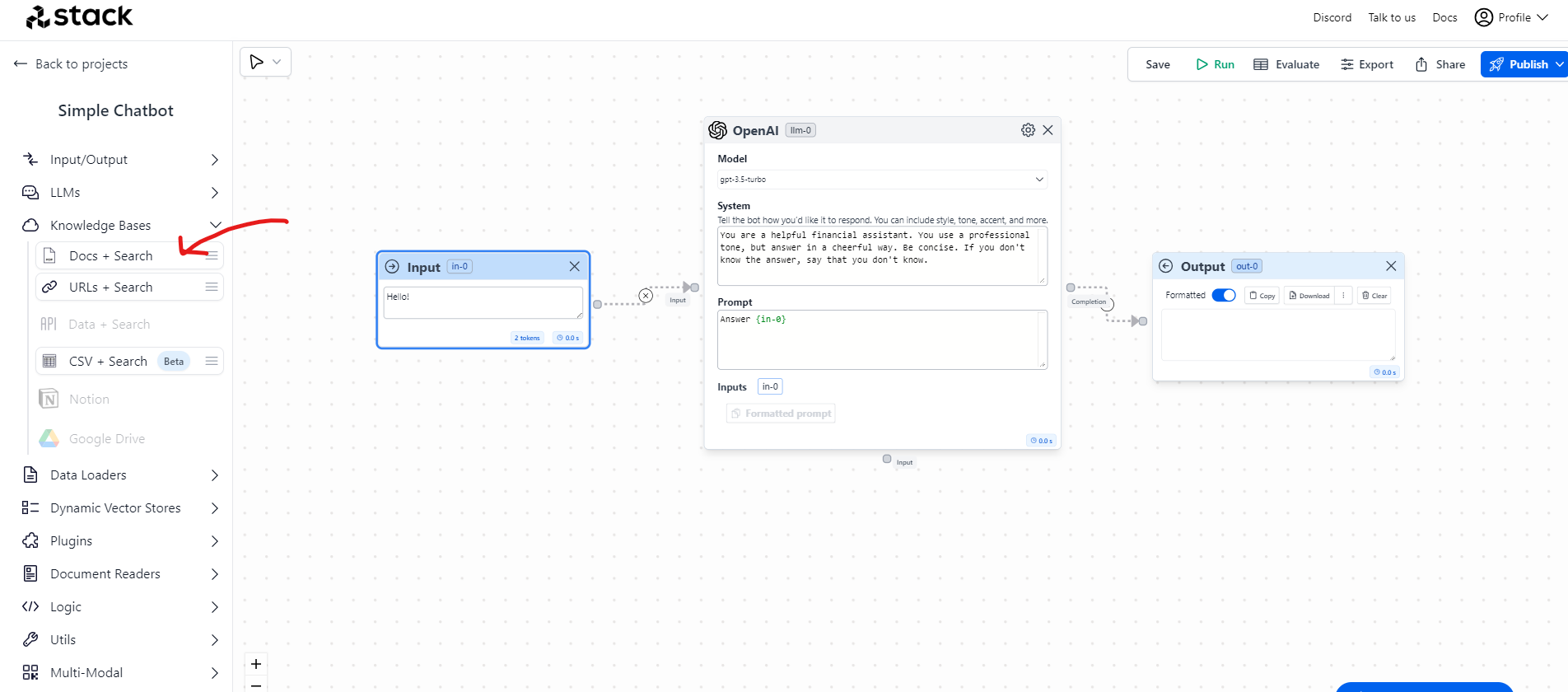
- Let’s add the Knowledge Bases. For that expand the Knowledge Base dropdown from the menu and add Docs + Search to the canvas
7. Click to upload the two PDFs. You can find the files to download here: llama2 paper.pdf and gpt4 paper.pdf.
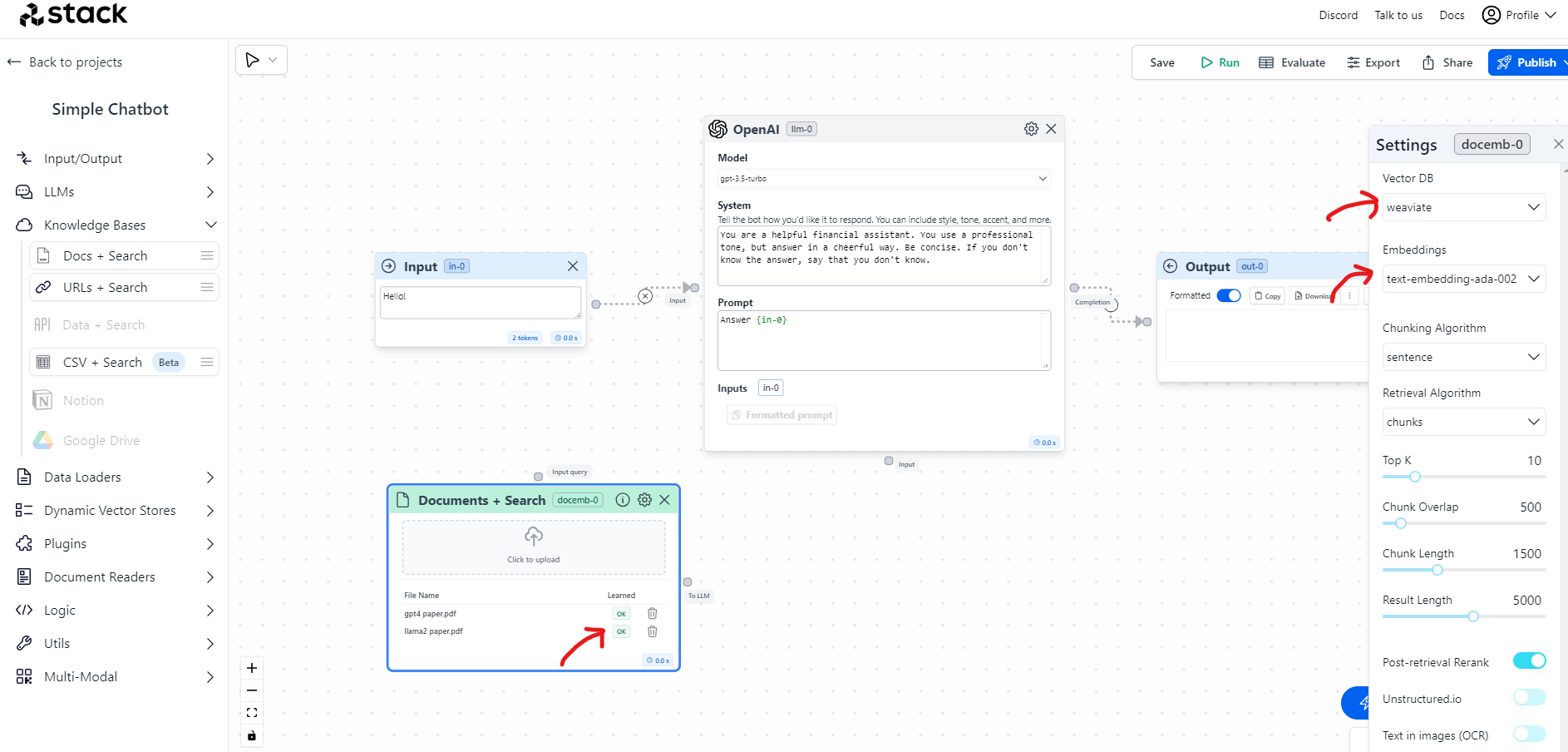
This node is pretty special. If you click in the settings you will see that it created a Vector DB for this project, it calls the Embeddings API to generate the tokens and after a few seconds, the status of both PDFs should be as Learned OK.
You could potentially play with the parameters, customize the Vector DB, or add thousands of documents. For this exercise, we will leave it as default.
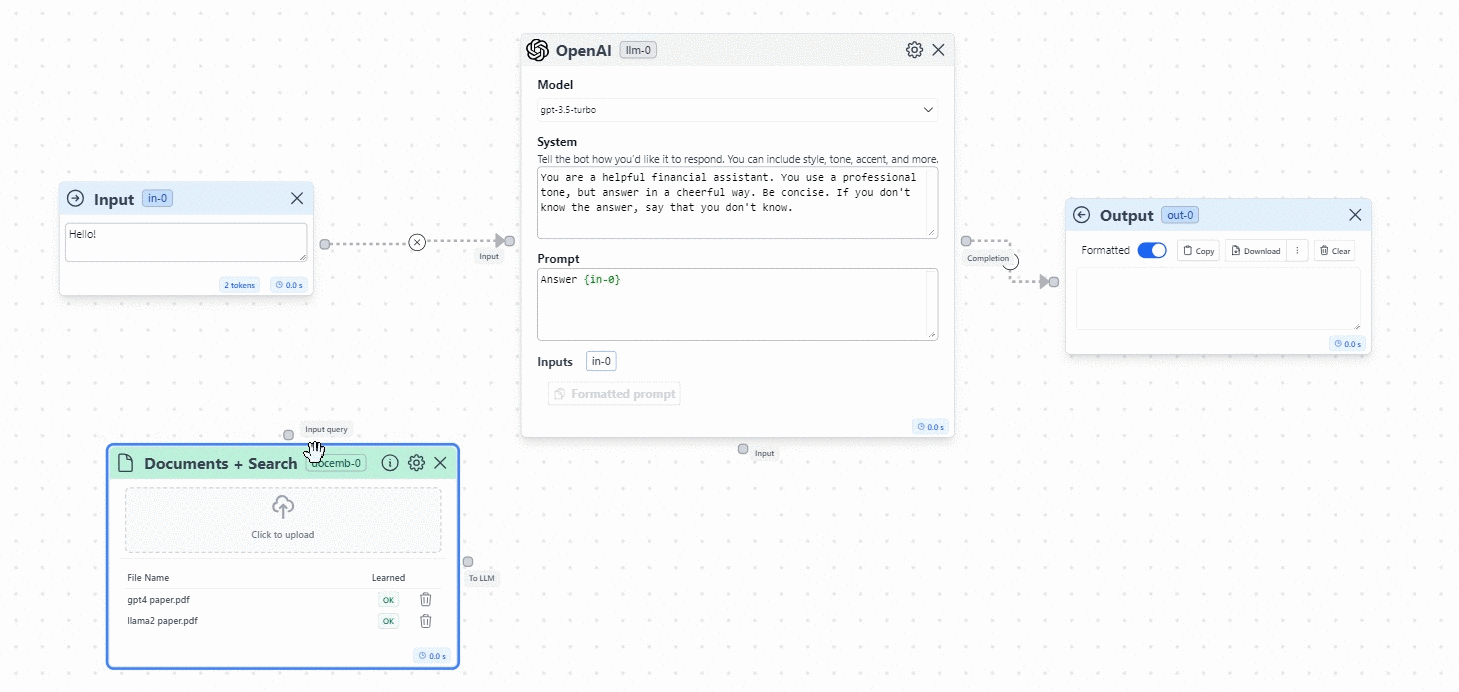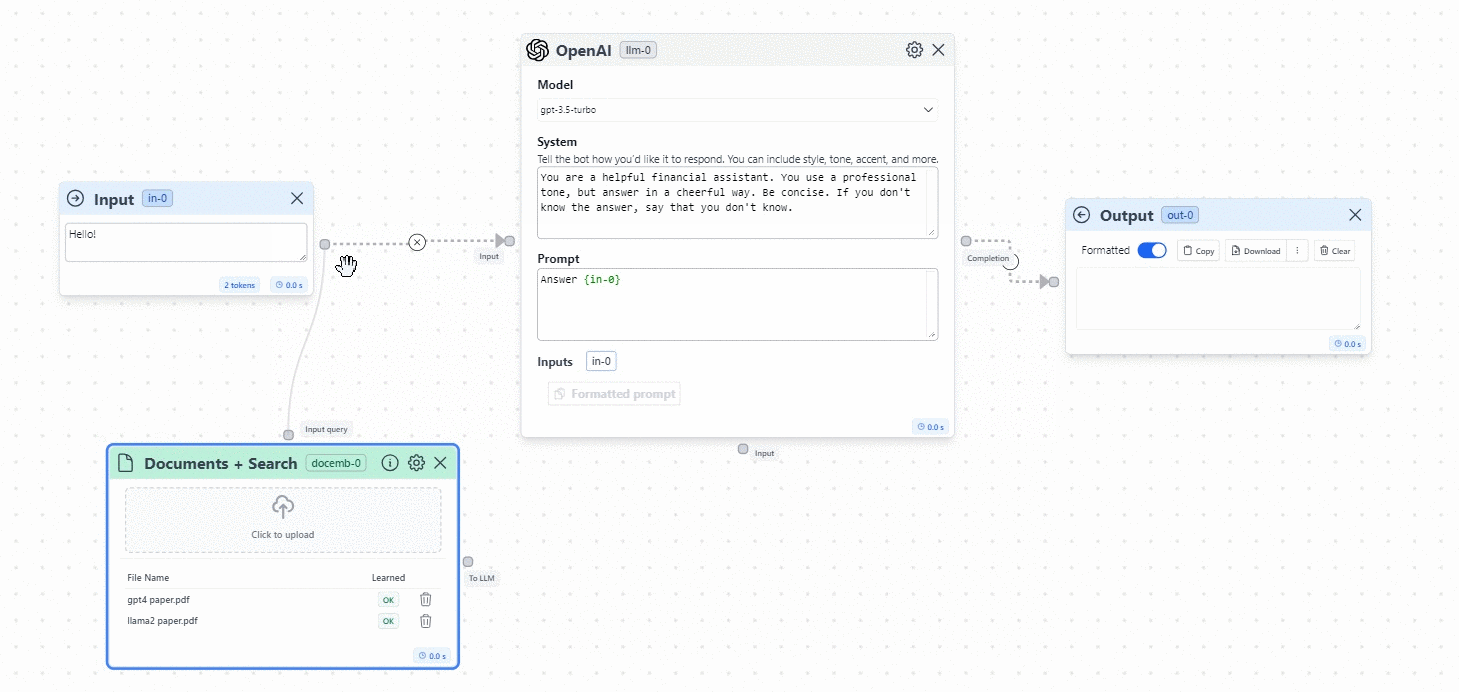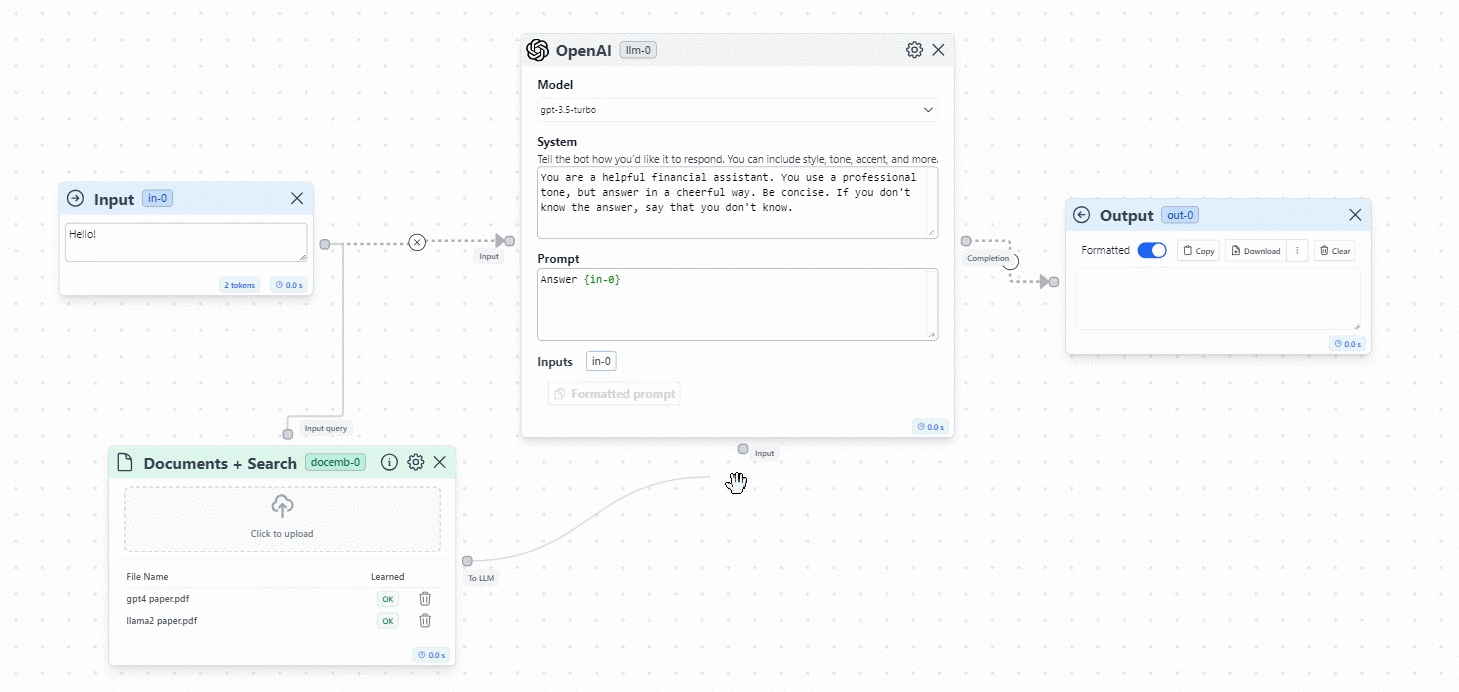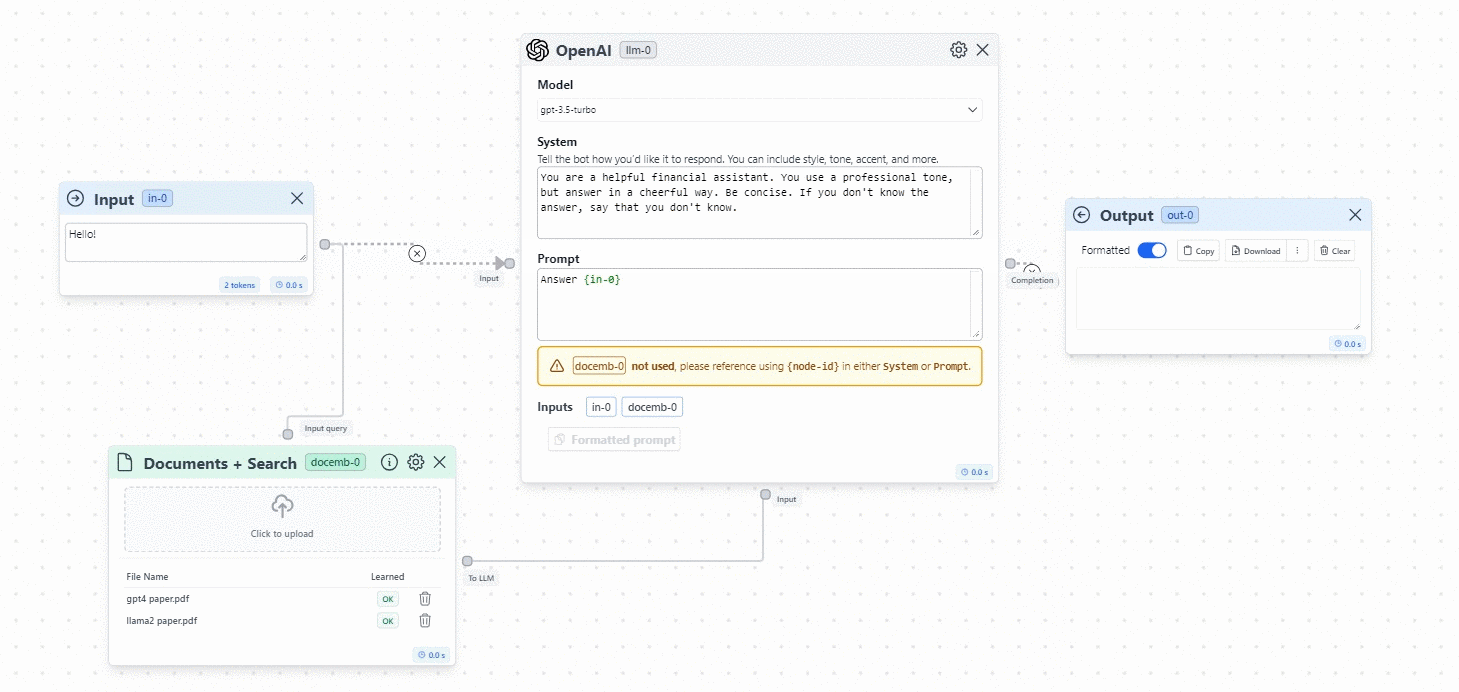
- Time to connect the Documents to the flow. You will create two connections:
- Connection 1: From the Documents node to the Input.
- Connection 2: From the Documents node to the Input of the OpenAI Model.
This will allow the application to search the information from the Input in the Documents that we feed to the model. See the image below:
- Time to write the prompts in the OpenAI model node. We will specify the instructions on where to get the information from and where to route it. Write the following two prompts:
System:
You are a helpful research university assistant. You will search in the Research Papers from your library and responds the questions. You use a professional tone, but answer in a cheerful way. Be concise. If you don't know the answer, say that you don't know.
Prompt:
The following is data extracted from PDF Research Papers about LLMs:
{docemb-0}
Answer {in-0}
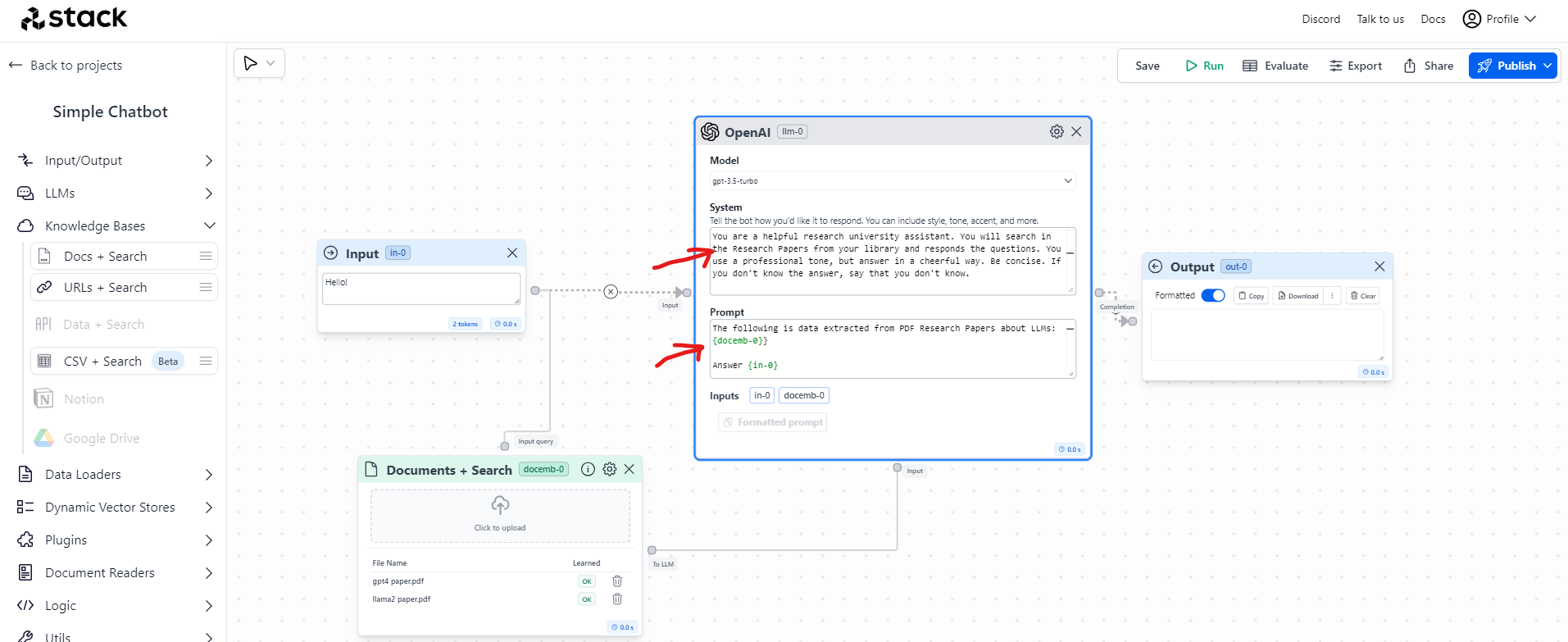
- Hit Save and then Publish
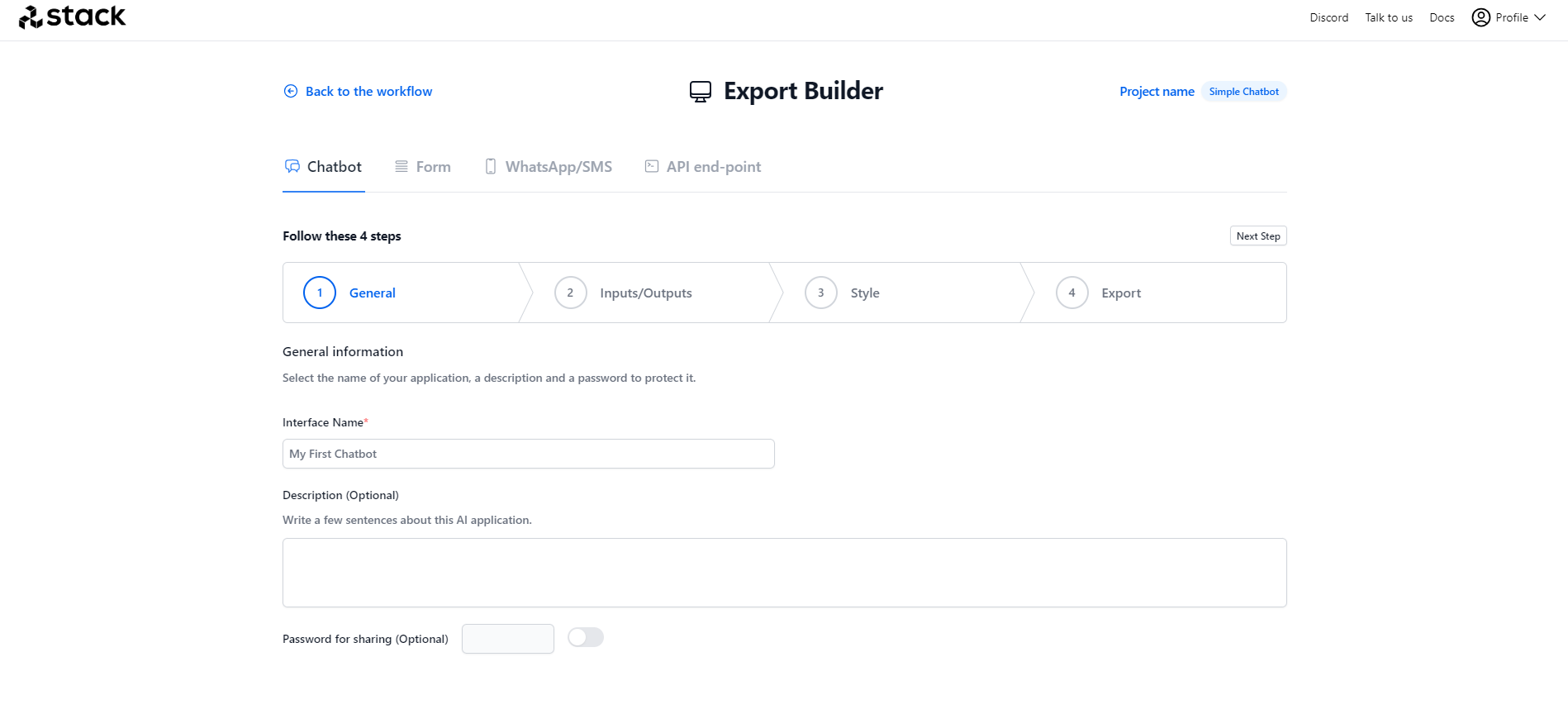
11. Click Export to get automatically the Chatbot interface built for us. There are multiple export options, including WhatsApp/SMS. For this exercise, we will select Chatbot and give it a name, for example, My First Chatbot
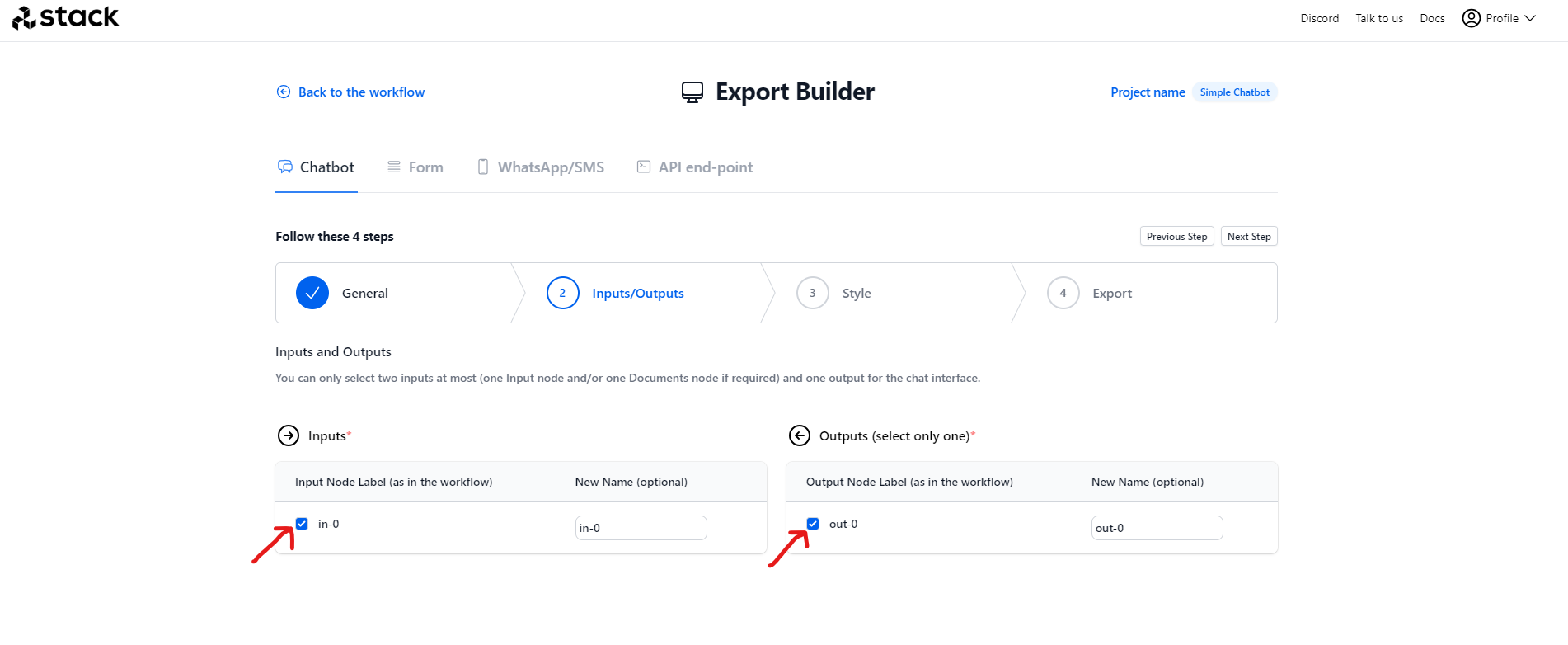
12. Next step you will need to select the inputs and outputs. Check the boxes and go to the Export step.
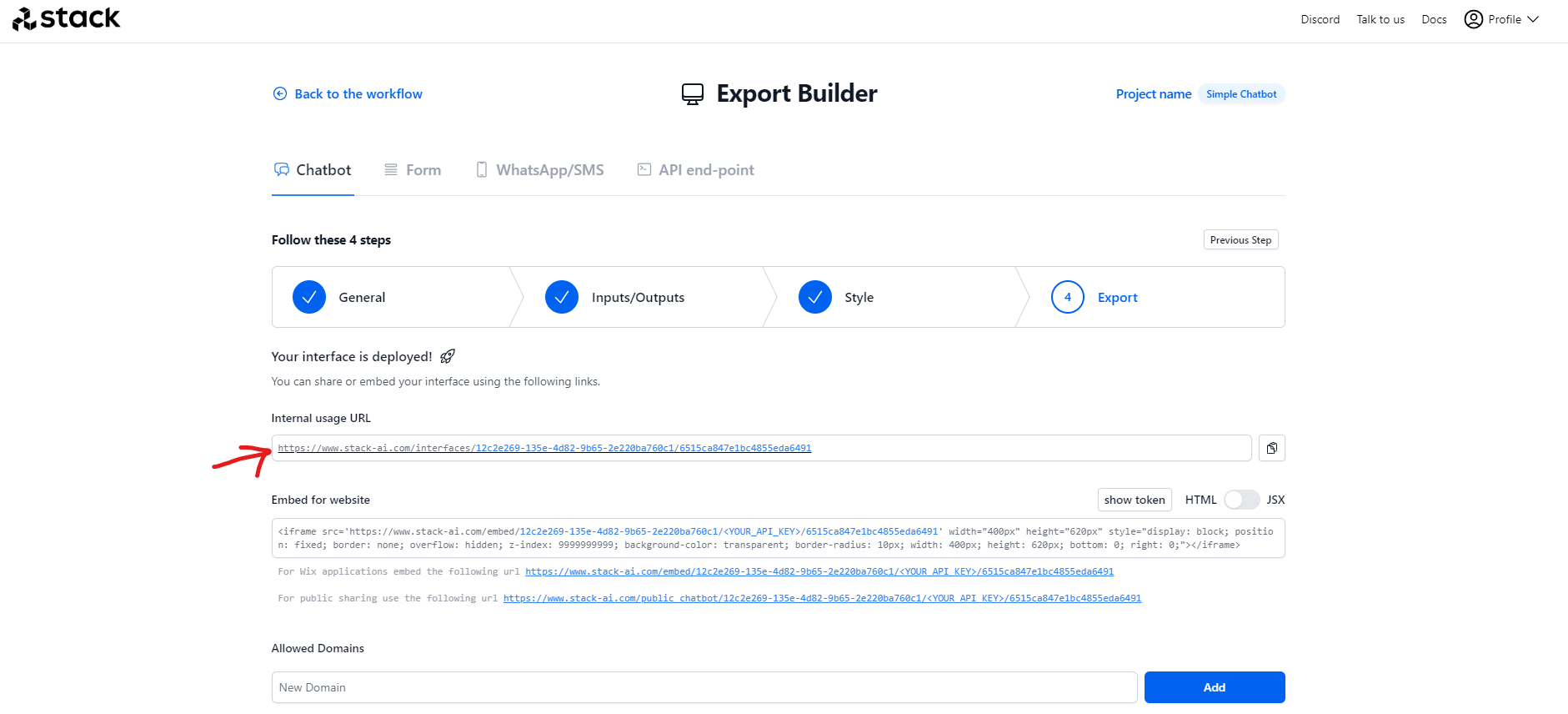
13. From the Export you will get the URL to access the Chatbot and also the iframe in case you would like to embed it on a website. Click on the URL to access your chatbot.
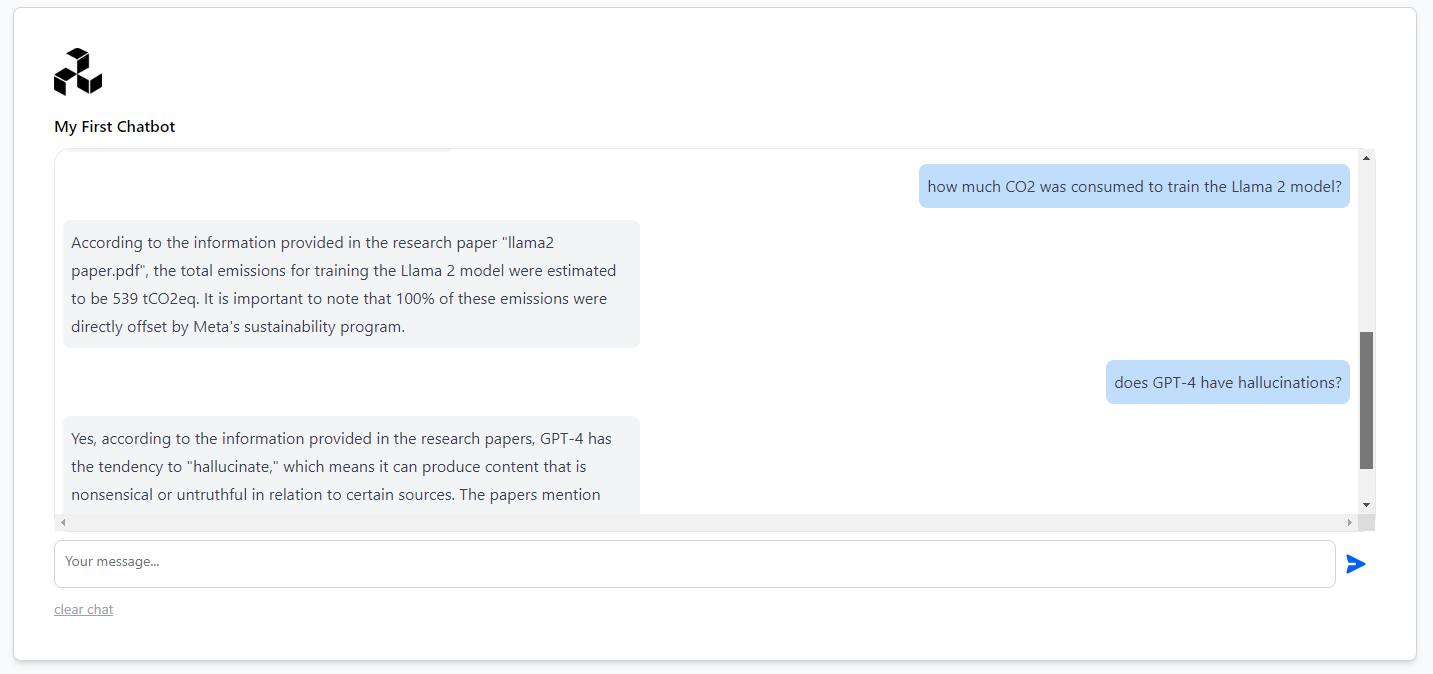
- And we are in our Chat! Let’s try the following questions:
- Question 1: who wrote the GPT-4 paper?
- Question 2: who wrote the Llama 2 paper?
- Question 3: which GPUs were used to train Llama 2?
- Question 4: how much CO2 was consumed to train the Llama 2 model?
- Question 5: is GPT4 multimodal and what is that?
- Question 6: is Llama 2 multimodal?
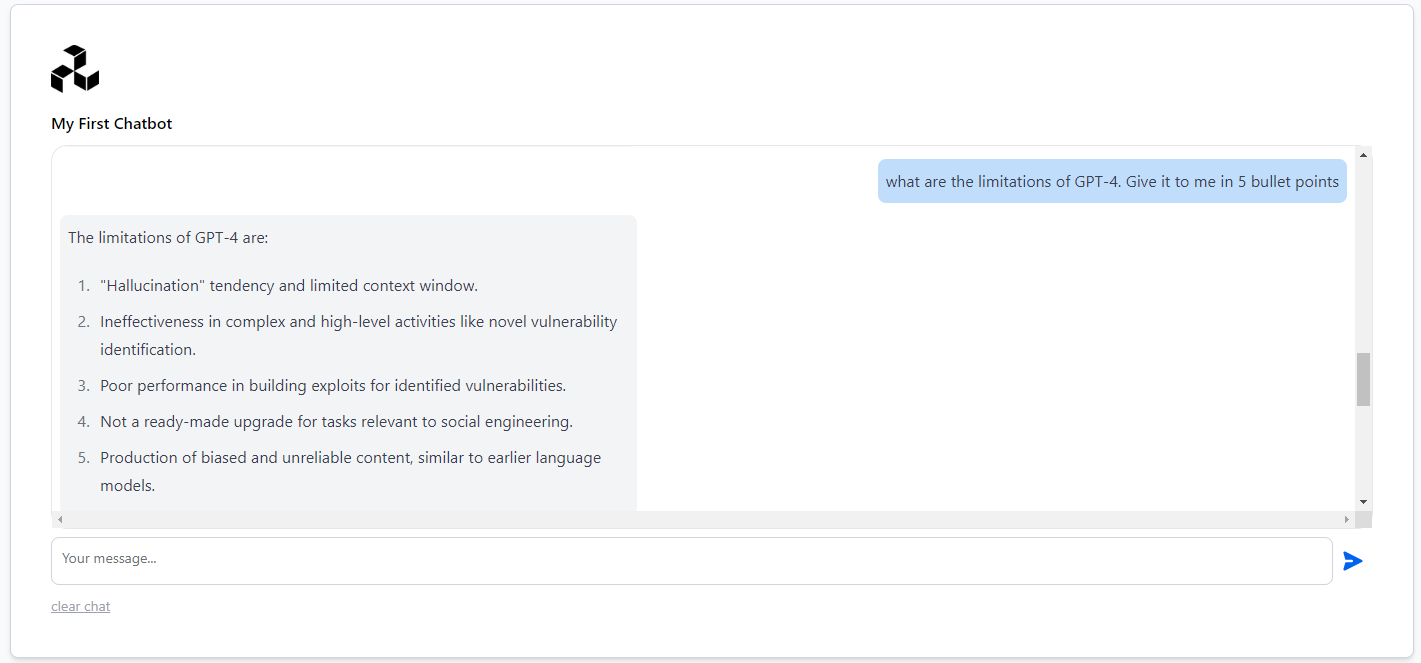
- Question 7: what are the limitations of GPT-4. Give it to me in 5 bullet points
- Question 8: what are the limitations of Llama 2. Give it to me in 5 bullet points
Try your own questions!
