
In recent years, there has been a lot of buzz surrounding large language models (LLMs). But what are they? Simply put, LLMs are computer systems that have been designed to learn the statistical properties of a text corpus in order to generate new text that mimics the style and content of the original text. In other words, LLMs are able to generate new text that is realistic and accurate and seems written by a real person. The AI looks at the last few words typed and tries to predict what word will come next. The predictions are based on probabilities, so the most likely prediction is chosen as the next word.
This process continues until the end of a sentence is reached or the maximum number of words is generated. Large language models are trained on billions of words to learn the relationships between terms. Once trained, they can generate new text that looks like a human wrote it.
How Large Language Models Work
At their heart, LLMs are based on a powerful Machine Learning technique known as Deep Learning. Deep learning is a subset of artificial intelligence (AI) that is capable of automatically learning complex patterns in data. Deep learning algorithms are inspired by the brain's ability to learn from experience and they are usually implemented using neural networks—computing systems that are structured very similarly to the brain.
One of the key differences between traditional machine learning algorithms and deep learning algorithms is that deep learning algorithms can scale to much larger datasets and they can learn from data that is unstructured or unlabeled. This makes them ideally suited for tasks like natural language processing (NLP), which is what LLMs are used for.
The Neural Network architecture used is called Transformers. This technique was first introduced in 2017 by researchers from Google Brain. There are different types of architectures, such as convolutional neural networks (CNNs) or Recurrent Neural Networks (RNNs). Those techniques have been useful for the past decade for use cases such as computer vision or language tasks like translation. CNNs and RNNs have several limitation and that's were transformers came in. Transformers network training can be parallelized and that opened the opportunity to train really big models for the first time.
The technique used with LLMs is called Autoregressive Model, which is a feed-forward model, which predicts the future word from a set of words given a context. It is essentially an AI searching the possibility space of the legal moves of the game of grammar one word at a time. LLMs take input text as input and transform it into what they predict the most useful result will be based on vast amounts of internet data training with patterns found throughout all types of writing styles, topics covered, etc., without much additional tuning or fine-grain control by humans.
In the following clip, Nvidia CEO Jensen Huang explains how LLMs work during his latest keynote at GTC 2022 a few days ago.
"Large Language Models are the most important AI models today."
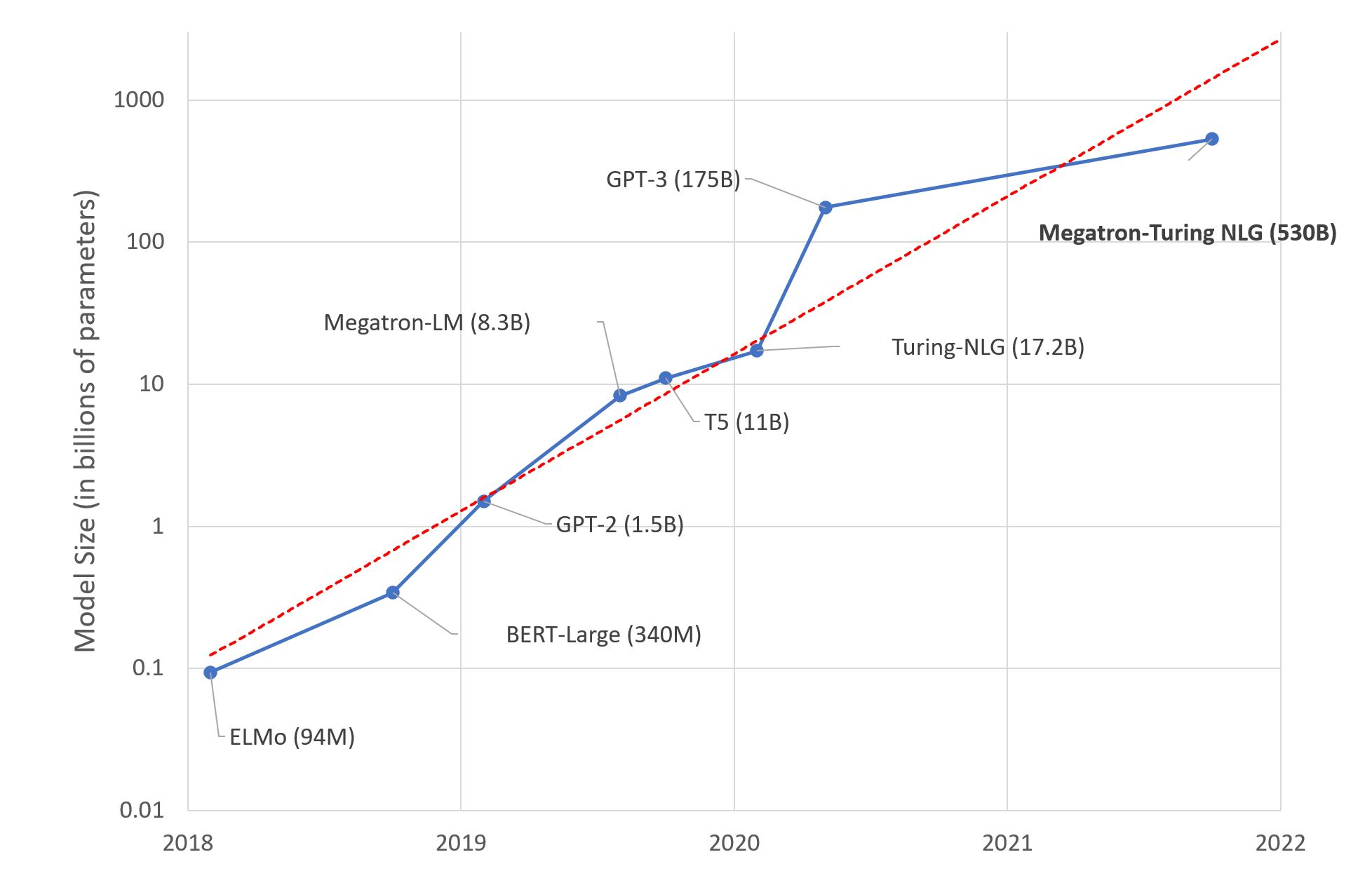
The race to develop the largest model
One of the most popular LLMs is GPT-3, trained by OpenAI. It has 175 billion parameters and was trained on 570 gigabytes of text. For comparison, its predecessor GPT-2 was over 100 times smaller at 1.5b billion parameters; however, this increase in size drastically changes the behavior of the model - it can now perform tasks that were not explicitly taught like translating sentences from English to French with few or no examples given by training data sets.
The final training dataset for GPT-3 contained a large portion of web pages from the internet, a giant collection of books, and all of Wikipedia. OpenAI worked with a supercomputer with thousands of GPUs to train the LLM and it still took months. The cost of training GPT-3 is not available for public access but it is estimated to be around $4.6 million for a training cycle, with reporters saying it could cost over $10 million. And that's just for training, one source estimates the cost of running GPT-3 on a single AWS instance at a minimum of $87,000 per year.
There is currently a race for big language models. The biggest one reported to date is Megatron, developed by Microsoft and Nvidia. It was announced as "the world's largest and most powerful generative language model". Megatron is a 530-billion-parameter model. There is a lot of debate if we need such big models or just select and evaluate small ones that can deliver the accuracy required for your use case. At the end of the day, hardware is expensive both for training and inference.
Why Large Language Models Are So Powerful
The reason why LLMs are so powerful is that they can build up an extremely rich internal representation of the language they are trained on. This internal representation captures not just the individual words in the language but also the relationships between those words—relationships like syntactic dependencies (e.g., noun-verb agreement) and semantic dependencies (e.g., the relationship between "dog" and "bark"). By capturing these relationships, LLMs are able to generate new text that sounds realistic because it respects these relationships.
The language model scaling study by OpenAI found that as the size of a computer's neural network improves, the performance also increases. LLMs are becoming more powerful, open source, versatile and faster to fine-tune.
As language models grow, their capabilities change in unexpected ways.
The power of LLMs comes when companies take existing LLMs already trained and tune them to create models for specific domains and tasks. Those companies will have a lot of value by using those models internally or offering them to their customers. They will combine LLMs massive training with their Domain-Specific datasets and use a new generation of tools to fine-tune those models. Many of those tools will be No-code AI tools and will allow users to modify the prompts.
In general, LLMs are hard to develop and maintain from scratch but multiple services and customization options are becoming available that do not require a full re-train of the model. If you need to specialize a model, there should only be very few reasons why one would train it from scratch.
There's a great interview from Reid Hoffman with the OpenAI CEO Sam Altman. They discuss the future of LLMs and this AI Technology. In this short clip, Sam highlights the tremendous business opportunity, comparing it to the introduction of the Internet or Mobile.
These systems will be able to generate new knowledge and advance humanity
Applications of Large Language Models
Large language models have many potential applications. They can be used to generate realistic news stories or help businesses automate customer service tasks by responding to questions in natural language. In addition, large language models can be used to create new songs or works of fiction. For example I used GPT-3 to write this blog. I created the narrative framework and I used LLMs to quickly, effortless and in a fun way write the entire body of the post from beginning to end.

New Startup Ecosystem based on LLMs
I've been very impressed with the number of LLM-based applications and startups that came out in recent years. Startups such as Cohere and AI21 Labs offer LLMs through APIs, similar to OpenAI. Other companies adopted LLMs in their products, such as AI Dungeon, Copy.ai, or Keeper Tax. OpenAI shared in March 2021 that GPT-3 was powering 300+ applications, and at that time they were in close beta.
I encourage you to watch my interview with Chris Lu, CTO, and co-founder of Copy.ai. You will see the power of creation and how entrepreneurs without previous AI experience can create entire businesses powered by AI.
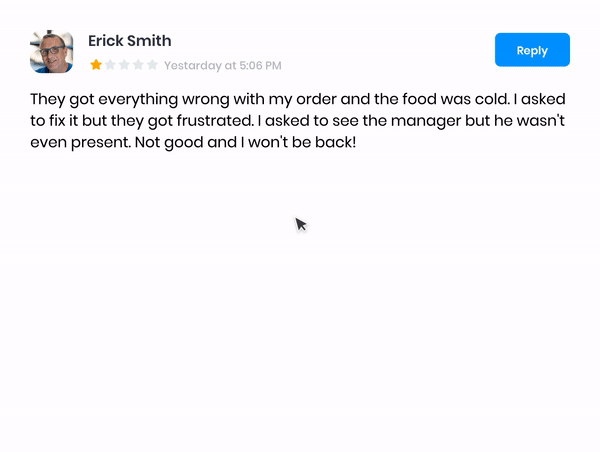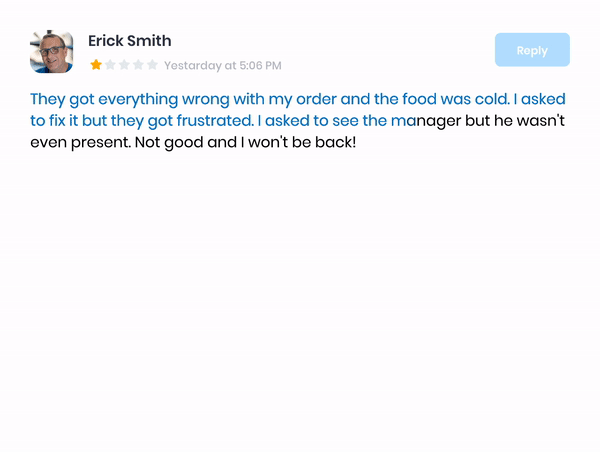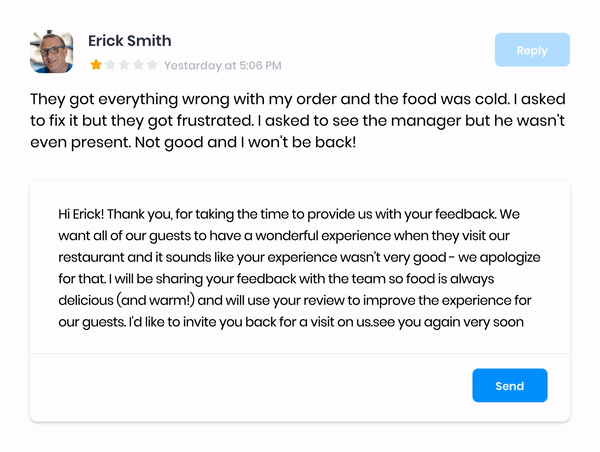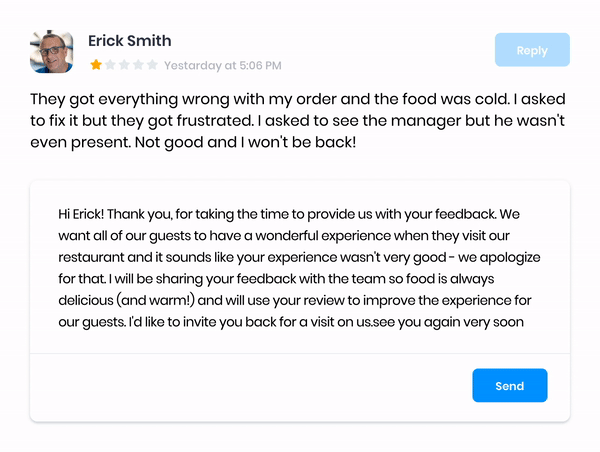
I even created an app called Replier.ai based on GPT-3 to respond to Google Reviews automatically.
Conclusion
Language models have been around for some time but only recently we have seen such rapid progress in their development thanks to deep learning progress and more powerful computing. We are in front of a potential technology revolution. Only this 2022, more than 10,000 research papers have been published in the space of transformers and a lot of algorithmic progress is being made.
The reason why large language models are so powerful is that they can build up an extremely rich internal representation of the language they are trained on—a representation that captures not just individual words but also the relationships between those words. This allows them to generate new text that is realistic because it respects these relationships. As LLMs continue to get better, we can expect to see them increasingly used for a variety of tasks and use cases. We are entering new paradigms and the performance of these models is surprising practitioners.